MMSEG: A Word Identification System for Mandarin Chinese Text Based on Two Variants of the Maximum Matching Algorithm
License: Free for noncommercial use
Copyright © 1996-2006 Chih-Hao Tsai (Email: )
Related Technical Reports
Related Research Reports
What's New
2000-03-12: I have re-analyzed and re-implemented algorithms used in MMSEG in a probably more useful program: A Chinese lexical scanner. Please visit the following page for details:
CScanner - A Chinese Lexical Scanner
Abstract
A problem in computational analysis of Chinese text is that there are no word boundaries in conventionally printed text. Since the word is such a fundamental linguistic unit, it is necessary to identify words in Chinese text so that higher-level analyses can be performed. The purpose of this study was to develop a word identification system based on two variations of the maximum matching algorithm. The system consisted of a lexicon, two matching algorithms, and four ambiguity resolution rules. It was found that the system successfully identified 98.41% of words in a sample consisting of 1013 words. Potential applications of this system will also be discussed in this article.
Introduction
The Chinese writing system, as Hung and Tzeng (1981) and DeFrancis (1984) pointed out, maps onto spoken language at both morphemic and syllabic levels. As a result, characters are distinct in written Chinese. On the other hand, word boundaries are absent from conventionally printed and written Chinese text.

Difficulties in the Word Identification Process
Since the word is such a fundamental linguistic unit, it is necessary to identify words in Chinese text so that computational analysis and processing of Chinese text can be performed. However, there are difficulties with the word identification process.

First of all, almost all characters can be one-character words by themselves. Moreover, they can join other characters to form multi-character words. This leads to a large amount of segmentation ambiguities. Second, compounding is the predominant word-formation device in modern Chinese. It is often difficult to tell whether a low-frequency compound is a word or phrase, and the lexicon can never exhaustively collect all low-frequency compounds. Third, the same pool of characters are also used in constructing proper names. Identifying proper names will be a problem, too. Finally, some specific morphological structures such as reduplication and A-not-A construction also need to be taken into consideration.
Except for a few exceptions (e.g. Huang, Ahrens, & Chen, 1993; Sproat and Shih, 1990), most word identification approaches share one common algorithm: matching (e.g., Chen & Liu, 1992; Fan & Tsai, 1988; Yeh & Lee, 1991). The basic strategy is to match the input character string with a large set of entries stored in a pre-compiled lexicon to find all (or part of) possible segmentations. Since there is usually only one correct segmentation, the ambiguity needs to be resolved.
The Maximum Matching Algorithm and Its Variants
Different studies differ in their ambiguity resolution algorithms. A very simple one which has been demonstrated to be very effective is the maximum matching algorithm (Chen & Liu, 1992). Maximum matching can take many forms.
Simple maximum matching. The basic form is to resolve the ambiguity of a single word (Yi-Ru Li, personal communication, January 14, 1995). For example, suppose C1, C2,... Cn represent characters in a string. We are at the beginning of the string and want to know where the words are. We first search the lexicon to see if _C1_ is a one-character word, then search _C1C2_ to see if it is a two-character word, and so on, until the combination is longer the longest words in the lexicon. The most plausible word will be the longest match. We take this word, then continue this process until the last word of the string is identified.
Complex maximum matching. Another variant of maximum matching done by Chen and Liu (1992) is more complex than the basic form. Their maximum matching rule says that the most plausible segmentation is the three-word chunk with maximum length. Again, we are at the beginning of a string and want to know where the words are. If there are ambiguous segmentations (e.g., _C1_ is a word, but _C1C2_ is also a word, and so on), then we look ahead two more words to find all possible three-word chunks beginning with _C1_ or _C1C2_. For example, if these are possible three-word chunks:
1. _C1_ _C2_ _C3C4_ 2. _C1C2_ _C3C4_ _C5_ 3. _C1C2_ _C3C4_ _C5C6_

The chunk with maximum length is the third one. The first word, _C1C2_ of the third chunk, will be considered as the correct one. We take this word, proceed to repeat this process from character C3, until the last word of the string is identified. Chen and Liu (1992) reported that this rule achieved 99.69% accuracy and 93.21% of the ambiguities were resolved by this rule.
Other Disambiguation Algorithms
Besides maximum matching, many other disambiguation algorithms have been proposed. Various information are used in the disambiguation process. For example, probability and statistics (Chen & Liu, 1992; Fan & Tsai, 1988), grammar (Yeh & Lee, 1991), and morphology (Chen & Liu, 1992). Most of them require a well-constructed lexicon with information such as character and word frequency, syntactic classes of words, and a set of grammar or morphological rules (e.g., Chinese Knowledge Information Processing Group [CKIP], 1993a, 1993b, 1993c).
MMSEG System Overview
The MMSEG system implemented both simple and complex forms of the maximum matching algorithm discussed earlier. Furthermore, to resolve ambiguities not resolved by the complex maximum matching algorithm, three more ambiguity resolution rules have been implemented.
One of which was proposed by Chen and Liu (1992), and the rest two were new. These rules will be discussed later. The system did not have special rules to handle proper names and specific morphological structures such as reduplication and A-not-A construction.
It has to be noted that MMSEG was not designed to be a "professional level" system whose goal is 100% correct identification. Rather, MMSEG should be viewed as a general platform on which new ambiguity resolution algorithms can be tested. Nevertheless, we will see that even the current version of MMSEG achieved very high percentage of accuracy, which was as high as those published on academic journals.
The Lexicon
The first part of the lexicon consisted of 124,499 multi-character entries. The lengths of the lexical entries varied from two characters to eight characters. See Appendix A for distribution of word lengths. The lexicon was simple a organized list of character strings. There were no additional information associated with each string. The basis of the lexicon was a list of 137,450 Chinese words maintained by the author (Tsai, 1996c). This list, in turn, was created by merging several Chinese word lists accessible on the Internet (Tsai, 1996a).
The second part of the lexicon consisted of 13,060 characters and their frequency of usage (Tsai, 1996b). Character frequency was used in the last ambiguity resolution rule.
Matching Algorithm
Simple. For character Cn in a string of characters, match the sub-string beginning with Cn with the lexicon and find all possible matches.
Complex. For character Cn in a string of characters, find all possible three-word chunks beginning with Cn, no matter whether there is any ambiguity with the first word. The three-word chunks were formed only when there was an ambiguity of the first word.
Ambiguity Resolution Rules
Four ambiguity resolution rules were used. The maximum matching rules applied to ambiguous segmentations from both simple and complex matching algorithms. The rest three rules did not (and could not) apply to ambiguous segmentations from the simple matching algorithm.
Rule 1: Maximum matching (Chen & Liu 1992). (a) Simple maximum matching: Pick the word with the maximum length. (b) Complex maximum matching: Pick the first word from the chunk with maximum length. If there are more than one chunks with maximum length, apply the next rule.
Rule 2: Largest average word length (Chen & Liu, 1992). At the end of each string, it is very likely to have chunks with only one or two words. For example, the following chunks have the same length and the same variance of word lengths.
1. _C1_ _C2_ _C3_ 2. _C1C2C3_

Rule 2 picks the first word from the chunk with largest average word length. In the above example, it picks _C1C2C3_ from the second chunk. The assumption of this rule is that it is more likely to encounter multi-character words than one-character words.
This rule is useful only for condition in which one or more word position in the chunks are empty. When the chunks are real three-word chunks, this rule is not useful. Because three-word chunks with the same total length will certainly have the same average length. Therefore we need another solution.
Rule 3: Smallest variance of word lengths (Chen & Liu, 1992). There are quite a few ambiguous conditions in which the Rule 1 and Rule 2 cannot resolve. For example, these two chunks have the same length:
1. _C1C2_ _C3C4_ _C5C6_ 2. _C1C2C3_ _C4_ _C5C6_
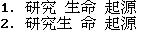
Rule 3 picks the first of the chunk with smallest variance of word lengths. In the above example, it picks _C1C2_ from the first chunk. This rule is exactly them as the one proposed by Chen and Liu (1992). (However, they applied this rule immediately after Rule 1.) The assumption of this rule is that word lengths are usually evenly distributed. If there are more than one chunks with the same value of smallest variance of word lengths, apply the next rule.
Rule 4: Largest sum of degree of morphemic freedom of one-character words. This example shows two chunks with the same length, variance, and average word length:
1. _C1_ _C2_ _C3C4_ 2. _C1_ _C2C3_ _C4_

Both chunks have two one-character words and one two-character word. Which one is more likely to be the correct one? Here we will focus on one-character words. Chinese characters differ in their degree of morphemic freedom. Some characters are rarely used as free morphemes, but others have larger degree of freedom. The frequency of occurrence of a character can serve as an index of its degree of morphemic freedom. A high frequency character is more likely to be a one-character word, and vice versa.
The formula used to calculate the sum of degree of morphemic freedom is to sum log(frequency) of all one-character word(s) in a chunk. The rationale for logarithm transformation is that the same amount of frequency difference does not have a consistent effect across all frequency ranges.
Rule 4 than picks the first word of the chunk with largest sum of log(frequency). Since it is very unlikely that two characters will have exactly the same frequency value, there should be no ambiguity after this rule has been applied.
Implementation
The MMSEG system was written in the C programming language.
Hardware and Software Environment. The MMSEG ran on an IBM compatible PC (486DX-33) with 1 MB main memory and 12 MB extended memory. The operating system was MS-DOS. The compiler used to build MMSEG was Turbo C++ 3.0. Including the executable, source code, lexicon, index, and the test data, the whole MMSEG system occupied about 1.5 MB disk space.
Results
A test sample consisting of 1013 words was used to test two sets of word identification algorithms of MMSEG. Table 1 shows the preliminary test results.
Table 1
Testing Results
_______________________________________________________
Identification Algorithm
Simple Complex
_______________________________________________________
Words identified (N2) 1012 1010
Correct identifications (N3) 966 994
Recall rate (N3/N1) 95.36% 98.12%
Precision rate (N3/N2) 95.45% 98.41%
_______________________________________________________
Note.
Number of words (N1) in the input sample is 1013.
Not surprisingly, even the simple maximum matching algorithm correctly identified over 95% of words in the test sample. This can be viewed as a base line of evaluating word identification algorithms.
The complex matching algorithm with four ambiguity resolution rules, correctly identified over 98% of words in the test sample. The performance was better than that of the simple matching algorithm.
Table 2 shows the success rate of each ambiguity resolution
rule. The first two rules resolved 90% of total ambiguous
instances and had relatively high success rates. Most (59.5%)
ambiguities were resolved by Rule 1. Rule 2 resolved 30.6%.
Rule 3 only resolved 1% of total ambiguities, and Rule 4
resolved 9%. The accuracy of these rules was relatively high in
general, but the accuracy of Rule 3 is slightly lower than
other rules.
Table 2
Accuracy of Each Ambiguity Resolution Rule
___________________________________________________
Ambiguity Resolution Rules
1 2 3 4
___________________________________________________
Identifications 400 245 6 82
Errors 5 4 2 4
Accuracy 98.75% 98.37% 66.67% 95.12%
___________________________________________________
Note.
Rule 1 = Maximum Matching.
Rule 2 = Largest Average Word Length.
Rule 3 = Smallest Variance of Word Lengths.
Rule 4 = Largest Sum of Degree of Morphemic Freedom
of One-Character Words.
Examples of errors:
Maximum Matching:
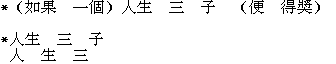
Largest Average Word Length:

Smallest Variance of Word Lengths:
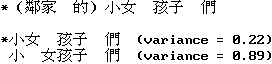
Largest Sum of Degree of Morphemic Freedom of One-Character Words:

Discussion
The accuracy of MMSEG system is as high as those published on academic journals. This finding indicates that MMSEG is a successful Chinese word identification system. The four ambiguity resolution rules have been demonstrated to be quite effective. Rule 1 (maximum matching) resolved most ambiguities. Specifically, Rule 3 (largest average word length) resolved more ambiguities than I have expected. And it's quite accurate. An examine of the data revealed that, as expected, most ambiguities Rule 3 resolved were end-sentence ambiguities. Surprisingly, very few ambiguities were resolved by Rule 2 (smallest variance of word lengths). This may have to do with the order of each rule. In an earlier version of MMSEG, Rule 3 was applied before Rule 2. In that version, Rule 2 resolved more ambiguities than it did in the current MMSEG. Rule 4 (largest sum of degree of morphemic freedom of one-character words) performed quite well. This indicates that statistical information is useful in disambiguation. As mentioned earlier, MMSEG was designed to be a general platform on which new ambiguity resolution algorithms can be tested. What I want to do in the future is to formulate hypotheses about how Chinese readers identify words and word boundaries during reading. I then can use MMSEG to test these algorithms. At the same time, I will also design experiments to collect data from human subjects. By comparing the performance of the computer program and human subjects, I can (hopefully) determine the psychological reality of each algorithm.
Availability and Portability
The source code and executable of MMSEG are available as a zip archive. Click on the link below to download:
mmseg.zip (532KB)
The source of mmseg can be compiled with gcc without modification, so it is basically platform-independent.
You are encouraged to use MMSEG for research purposes. You are also encouraged to use MMSEG to develop FREE software, as long as you acknowledge me and MMSEG appropriately in your source code and documentation and send me a copy of your software. However, individual licensing is required for any commercial use of MMSEG.
MMSEG, Libtabe, and XCIN
Libtabe is a C library released by the TaBE project led by Pai-Hsiang Hsiao. Libtabe provides unified interface and supportive functions for handling Chinese characters, sounds, words and sentences.
The set of word identification algorithms used by MMSEG has been implemented by Pai-Hsiang Hsiao in the latest release of libtabe to provide word identification capability. With this capability in libtabe, Pai-Hsiang Hsiao was able to develope a module called bims, which can intelligently recover the correct characters from a string of Mandarin syllables at a very high accuracy. As is well known, homophones are very common among Chinese characters. Libtabe's achievement, in this context, is very significant.
The latest version of XCIN, an XIM (X Input Method) server which is widely used in X Window system to provide Chinese input functionality, now integrates with libtabe to provide an intelligent phonetic input module. It turns out that this module is as good as commercial products.
References
Chen, K. J., & Liu, S. H. (1992). Word identification for Mandarin Chinese sentences. Proceedings of the Fifteenth International Conference on Computational Linguistics, Nantes: COLING-92.
Chinese Knowledge Information Processing Group. (1993a). Corpus based frequency count of characters in journal Chinese (CKIP Technical Report No. 93-01). Taipei, Taiwan: Academia Sinica.
Chinese Knowledge Information Processing Group. (1993b). Corpus based frequency count of words in journal Chinese (CKIP Technical Report No.93-02). Taipei, Taiwan: Academia Sinica.
Chinese Knowledge Information Processing Group. (1993c). The CKIP categorical classification of Mandaring Chinese (CKIP Technical Report No. 93-05). Taipei, Taiwan: Academia Sinica.
DeFrancis, J. (1984). The Chinese language: Facts and fantasy. Honolulu, HI: University of Hawaii Press.
Fan, C. K., & Tsai, W. H. (1988). Automatic word identification in Chinese sentences by the relaxation technique. Computer Processing of Chinese & Oriental Languages, 4, 33-56.
Huang, C. R., Ahrens, K., & K. J. Chen. (1993, December). A data-driven approach to psychological reality of the mental lexicon: Two studies on Chinese corpus linguistics. Paper presented at the International Conference on the Biological and Psychological Basis of Language, Taipei, Taiwan.
Hung, D. L, & Tzeng, O. (1981). Orthographic variations and visual information processing. Psychological Bulletin, 90, 377-414.
Sproat, R., & Shih, C. (1990). A Statistical method for finding word boundaries in Chinese text. Computer Processing of Chinese & Oriental Languages, 4, 336-351.
Tsai, C. H. (1996a). A review of Chinese word lists accessible on the Internet [On- line]. Available: http://technology.chtsai.org/wordlist/
Tsai, C. H. (1996b). Frequency and stroke counts of Chinese characters [On-line]. Available: http://technology.chtsai.org/charfreq/
Tsai, C. H. (1996c). Tsai's list of Chinese words [On-line]. Available: http://technology.chtsai.org/wordlist/tsaiword.zip
Yeh, C. L., & Lee, H. J. (1991). Rule-based word identification for Mandarin Chinese sentences - A unification approach. Computer Processing of Chinese & Oriental Languages, 5, 97-118.
Installing and Executing MMSEG
The current implementation of MMSEG does not load the lexicon into computer memory. It only loads index into memory and search the lexicon on hard disk. Therefore, it is recommended to have a fast hard disk and have a disk cache disk cache installed. And a fast Pentium PC is always preferred.
To install, uncompress mmseg.zip to any folder.
Executing mmseg:
MMSEG file1 file1 path [complexity] [progress note]
file1: source file to be processed
file2: target file to write segmented text to
path: where the lexicon can be found
complexity: Complexity of matching algorithm:
simple Simple (1 word) matching (default)
complex Complex (3-word chunk) matching
progress note (for complex matching only): Progress note sent to
standard output (screen) during segmentation:
verbose Display (1) All ambiguous segmentations and the
length, variance of word lengths, average word length, and sum
of log(frequency) for each each segmentation (2) Number of
ambiguous segmentations not resolved by each disambiguation
rule, and at which rule the ambiguity is resolved
standard Display (2) only
quiet None of the above information will be displayed
Example: MMSEG in.txt out.txt .\lexicon\ complex quiet
Author Note
This paper was a combination of the two term projects for "Topics in Computational Linguistics" and "Seminar in Chinese Linguistics" taught by Professor Chin-Chuan Cheng at University of Illinois at Urbana-Champaign. In 1995, when I initiated the idea of writing a Chinese word identification program, I knew little about computational linguistics. With the knowledge I have gained from his courses during the past two semesters, I am now capable of implementing such a system. I am also grateful to Professor George McConkie at University of Illinois, Professor Chu-Ren Huang at Academia Sinica, Taiwan, Professor Richard Sproat at AT & T Bell Laboratories, and Yi-Ru Li who was a graduate student in computer science at National Cheng-Kung University, Taiwan, for their insightful suggestions. I also want to thank Shih-Kun Huang at National Chiao-Tung University (now at Academia Sinica), Taiwan, who calculated the frequency counts of Chinese characters from a huge corpus consisting of all BIG-5 encoded articles posted to Usenet during 1994-95 and made his data available to the public.
Links
ROCLING (The Association for Computational Linguistics and Chinese Language Processing), Taiwan
Chinese Knowledge Information Processing Group, Institute of Information Science, Academia Sinica, Taiwan
Online Corpus Search Service, Institute of Information Science, Academia Sinica, Taiwan
COLIPS (Chinese and Oriental Languages Information Processing Society), Singapore
Guo Jin's Research Papers and Leisure Writings, Guo Jin, Institute of Systems Science, National University of Singapore
The Chinese PH Corpus, Guo Jin, Institute of Systems Science, National University of Singapore
Chinese Usenet Archive (FTP), Department of Computer Science and Information Engineering, National Chiao-Tung University, Taiwan
Chang, C. H. (1994). A pilot study on automatic Chinese spelling error correction, Communications of COLIPS, 4(2), 143-149.
Chang, C. H. (1995, December). A new approach for automatic Chinese spelling correction, Proceedings of Natural Language Processing Pacific Rim Symposium '95(NLPRS'95) (pp. 278-283), Seoul, Korea. [One of the Best Paper Award recipients]